KADOKAWA Connected / ドワンゴの @saka1 です。最近はデータ基盤の保守等に携わっています。
今回はStreamlitというWebアプリケーションフレームワークを使い、Snowflake上のテーブルの利用状況を測定するダッシュボードを作ってみました。
データの需要はいつの間にか変化している問題
データ活用を進めるためには、データの整備が必要です。無いデータは分析できないので……。一方で、ただデータを基盤上に整備するだけだと、そのデータがどれぐらい有用なのかは判断が難しいです。
整備当初は有用でみんなが見ていた(かもしれない)テーブルも、しばらく経つと人気がなくなっていることがあります。 ひどい時には、実は誰も見ていないデータを導出するためのデータパイプラインを、エンジニアが必死でお守りしている事さえあるかもしれません。
データの整備というとき、ただデータを増やしてビジネスサイドの要望に応え続ける一方だと、いずれ破綻します。保守コストの増大にデータの価値が追いつかなくなる1からです(我々自身あんまり他人事ではないです)。
破綻を防ぐには、有用なデータを増やす一方で使われなくなったデータの廃止を進めるなど、ライフサイクルを計画していく必要があります。そのための基礎になるのが測定です。
※ やや余談ですが、この辺りは普通のWebサービスなどとも似ている気がします。ビジネスの改善のためにフィードバックサイクルを作り強化する必要がある一方で、データ整備自体も一種の(典型的には社内向けの)サービスとして継続的な改善をかける必要があるのです。
参考例: 現実の利用状況をデータマネジメントに活かす
メルカリの @__hiza__ さんは、この辺りのデータマネジメントについて、実際の利用状況をINFORMATION_SCHEMAから取得可視化するアプローチを提案なさっています。 データマネジメント自体をデータドリブンに行うのは、とても筋が良さそうに感じました。
この記事のお題
この記事でもほぼ同様のことをしてみようと思います。つまり、テーブル単位で利用状況を測定してみることで、各データのユーザ利用状況を可視化します。 もっとも、同じことをやっても面白くないので、ちょっとだけお題を改変しました。
- BigQueryではなくSnowflakeでの測定を行う
- これは単に我々のデータ基盤で採用しているのがSnowflakeだからです
- Streamlitによってダッシュボードの形にまとめてみる
- ユニークユーザ数(UU)をグラフ化してみることにします
Pythonはあまり詳しくないので雰囲気で書いてるところがあります。許してください……。
Streamlit
Streamlitは、ダッシュボードのようなものをPythonで表現するためのWebアプリケーションフレームワークです。 このフレームワークの動きは興味深いもので、いわゆるリアクティブプログラミングのような発想が入っているようです。
- StreamlitのAPIを呼ぶことで、入出力のウィジェットをWebページ上に設置できる
- 入力値が変化するとPythonコード全体が再評価される。それによって出力結果を変えることができる
- 入力ウィジェットとしては例えばスライダー、出力ウィジェットとしては表や図などが標準で提供されている
再評価の部分はStreamlitが自動的にやってくれるので、アプリ開発者は入力ウィジェットの値に応じて計算を行い出力につなぐことに注力できます。ダッシュボード記述に特化しているのもあり、例えばHTMLやCSSを触る必要はなく、シンプルな記述です。
簡単な例としてモンテカルロ法を使った円周率計算を実装してみました2。以下のPythonコードをStreamlitで実行します。
import itertools import random import matplotlib.pyplot as plt import numpy as np import pandas as pd import seaborn as sns import streamlit as st def generate_sample_df(n): def r(): while True: yield random.random() return pd.DataFrame( { "x": itertools.islice(r(), 0, n), "y": itertools.islice(r(), 0, n), }, dtype=np.float32, ) # 入力(この場合はスライダー)の設定 n = st.slider("Sample size", 0, 1000, 200) # n点からなるサンプルを生成し、それぞれが円の内側にあるかどうかを判定しておく df = generate_sample_df(n) df["is_in_circle"] = (df["x"] ** 2 + df["y"] ** 2) < 1**2 # テキストの表示 st.write("Pi ≒ ", 4 * len(df[df["is_in_circle"]]) / len(df)) # matplotlibでの描画結果の表示 fig = plt.figure() sns.scatterplot(x="x", y="y", data=df, hue="is_in_circle") st.pyplot(fig) # DataFrameの表示 st.write("Head of df") st.dataframe(df.head(10))
実行は単純で、ローカルで streamlit run monte.py などとやるとアプリケーションサーバが立ち上がります。すると、こんなWebページが得られます。
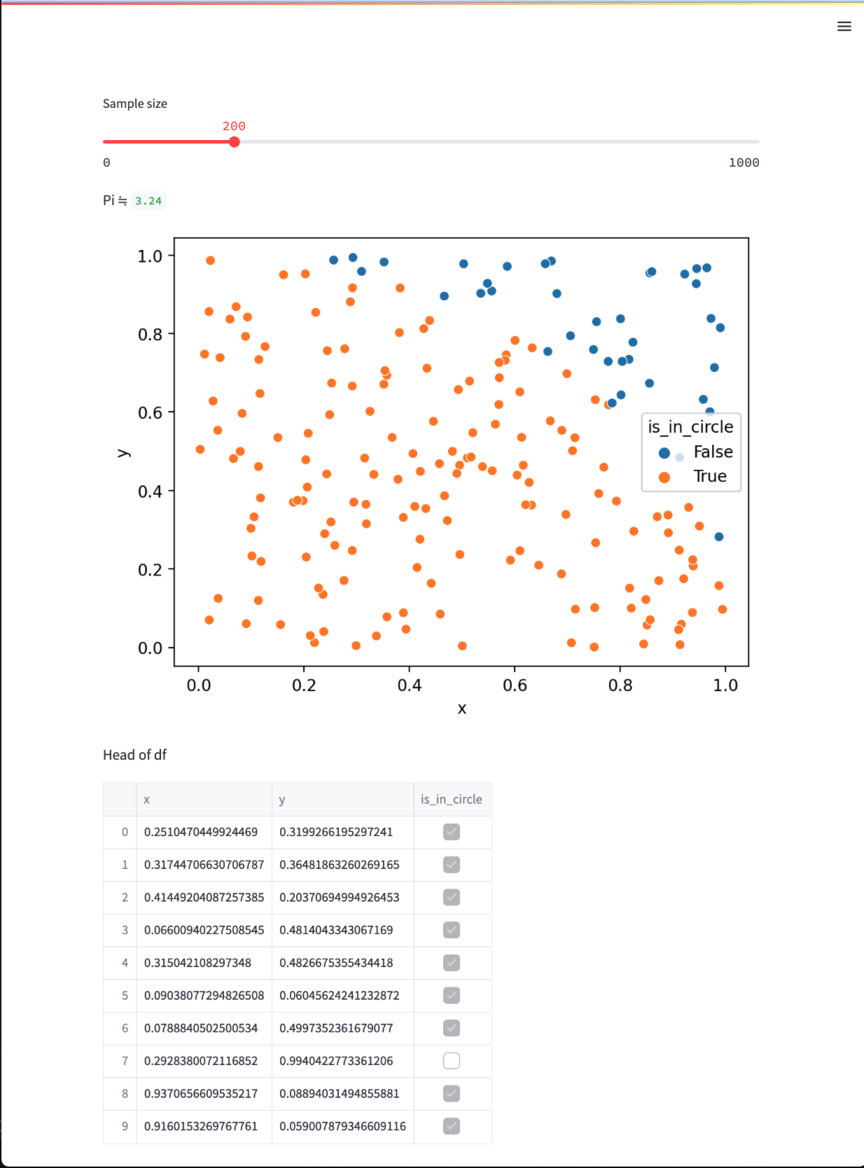
Streamlitがやっていることは st.slider で設定したスライダーの値がユーザの操作で変わるたびに、プログラム全体を再実行することです。結果的に n に依存する箇所もすべてが再評価されるので再描画が完了します。
そこさえ押さえれば(Pandasを知っている前提にはなりますが)なんとなく読めちゃうんじゃないでしょうか。
Snowflakeにおける利用状況の取得
Snowflakeでは、INFORMATION_SCHEMAと別に、ACCOUNT_USAGEビューが提供されています。 https://docs.snowflake.com/ja/sql-reference/account-usage.html
ここでいうアカウントとはSnowflakeが契約者に払い出すテナントで、他のもので例えるならAWSアカウントとかに近いものです。 ACCOUNT_USAGEからはアカウント全体での様々な情報が取得できますが、今回のお題で利用できそうなのはACCESS_HISTORYビューです。
このビューはアカウント全体で
- 誰が
- どんなクエリを発行し
- どのテーブルのどのカラムにアクセスしたか
これらについての情報を提供します。今回の用途にぴったりです。
StreamlitからSnowflakeのSQLを発行する
さて、前述の2つを組み合わせてStreamlitアプリケーションを作ります。といっても、技術的にそれほど複雑なことはありません。なぜならStreamlitはPythonで任意のコードが実行でき、そしてPythonコード上からはSnowflakeはごく普通のRDBMSのように扱えるからです。
入力パラメータとして多少実用感があるかなと思い今回選んだのは抽出対象区間です。この期間にテーブルを利用したユニークユーザ数で人気テーブルランキングを出力してみることにします。
今回は以下のようなコードを書きました。
import datetime import os from pathlib import Path import matplotlib.pyplot as plt import seaborn as sns import snowflake.connector import streamlit as st from dotenv import load_dotenv load_dotenv() ACCOUNT = os.getenv("SNOWFLAKE_ACCOUNT") USERNAME = os.environ.get("SNOWFLAKE_USERNAME") PASSWORD = os.environ.get("SNOWFLAKE_PASSWORD") assert ACCOUNT is not None assert USERNAME is not None assert PASSWORD is not None def fetch_data(since=datetime.date(2022, 1, 1), until=datetime.date(2022, 2, 1)): try: ctx = snowflake.connector.connect( account=ACCOUNT, user=USERNAME, password=PASSWORD, network_timeout=30, ) sql = Path("./uu_query.sql").read_text() cur = ctx.cursor() cur.execute( sql, ( since, until, ), ) df = cur.fetch_pandas_all() return df finally: cur.close() with st.form(key="uu_form"): query_start_since = st.date_input("UU計算(始点)", datetime.date(2023, 1, 1)) query_start_until = st.date_input("UU計算(終点)", datetime.date(2023, 1, 7)) submit = st.form_submit_button(label="UU抽出") if submit: df = fetch_data(since=query_start_since, until=query_start_until) fig = plt.figure(figsize=(6, 18)) sns.set_theme() sns.set(font_scale=0.8) sns.barplot(x="UU", y="TABLE_NAME", data=df) st.pyplot(fig) # DataFrameを表形式で表示 st.write("Top5") st.dataframe(df.head(5))
基本的にはデータを引っ張ってきて簡単に加工して可視化しているだけですが、いくつかの点を補足します。
Streamlitのform
まずはformについてです。formはStreamlitの比較的最近の機能らしく、要するにコードの再評価をボタンを押すまで遅延させるためのものです。
date_inputを含め普通のStreamlitの入力用オブジェクトは、入力を変えるたびにコードの再評価が走ります。しかし、この処理が重かったとするとユーザは不快ですし重い計算をするインフラも大変です。ここでformを使うと、submitを押下した後のみ再評価されるようにできます。今回の用途でいうと、日付設定を動かすたびにSQLが発行され計算リソースを食う挙動を避けられます。
UU計算用のSQL
次にUU計算用のSQLについてです。PythonからSnowflakeにSQLを発行するにはPythonコネクタを使います。
https://docs.snowflake.com/ja/user-guide/python-connector.html
このコネクタライブラリはPEP-249を実装しているので、一般的なPythonでデータベースを触るコードと書くことはほぼ同じです。ちょっとした便利関数として、SQLの実行結果をPandasのDataFrameに変換してくれる関数fetch_pandas_allがあります。今回はこれも使ってみました。
外部ファイルに置いているuu_query.sqlは、おおむね以下のようになっています。
with summary_table as ( select table_name from account_usage.tables where table_schema ilike 'summary' and deleted is null ), table_access_event as ( select user_name, query_start_time, split_part(boa.value:objectName, '.', 3) as table_name from access_history hist, lateral flatten(input => hist.base_objects_accessed) boa where boa.value:objectDomain = 'Table' ), uu_per_table as ( select table_name, count(distinct user_name) as uu from table_access_event where query_start_time between %s::date and %s::date group by table_name ) select st.table_name as table_name, nvl(uu, 0) as uu from summary_table st left join uu_per_table ut on st.table_name = ut.table_name order by uu desc, table_name;
このクエリが何をやっているかですが、まずtable_access_event式ではACCESS_HISTORYビューからテーブルへのアクセスを全て抽出しています。
アクセス対象はbase_objects_accessedカラムで特定できますが、このカラムはVARIANT型の配列になっています。VARIANTはSnowflakeにおける半構造化データ型です。つまりJSONのようなものです。1つのクエリでは複数のテーブルやビューなど(Snowflakeではそれらをまとめてオブジェクトと呼ぶようです)にアクセスすることがあるので、その情報を全て配列の形で詰め込んでいるようです。
配列を分解したいときにSnowflakeではFLATTEN関数を使います。分解した結果のうち今回はテーブルへのアクセスだけに関心があるので、where boa.value:objectDomain = 'Table'でフィルタしています。
split_part(boa.value:objectName, '.', 3) as table_nameは少し手抜きしました。Snowflakeにおける完全修飾されたオブジェクト名は <データベース名>.<スキーマ名>.<オブジェクト名> の形式をとるため.で分解して3番目をとっていますが、Snowflakeはクオートすることでほぼ任意の文字を識別名に使うことができます。したがって.での分割は不正確ですが、今回のデモの範囲では問題にならないのでこのままにしておきます。
summary_tables式では抽出対象のテーブルを指定しています。今回はsummaryというスキーマにあるテーブルのうち削除されていないものを対象にします。
※ このSQLは社内データの都合上いくつかの改変を行っています(結果に本質的な影響はありません)。
その他
- 環境変数の読み出しにはdotenvを使っています
%s::dateはCAST式によるDATE型への型変換のシンタックスシュガーです。%sはSQL発行のためのプレースホルダですが、これはPEP-249の仕様に基づいています。
出力例
例えばこういった出力が得られました。テーブル名には外部に出せない部分もあったので黒塗りにし、グラフの上の方だけ切り取ったものを掲載しています。
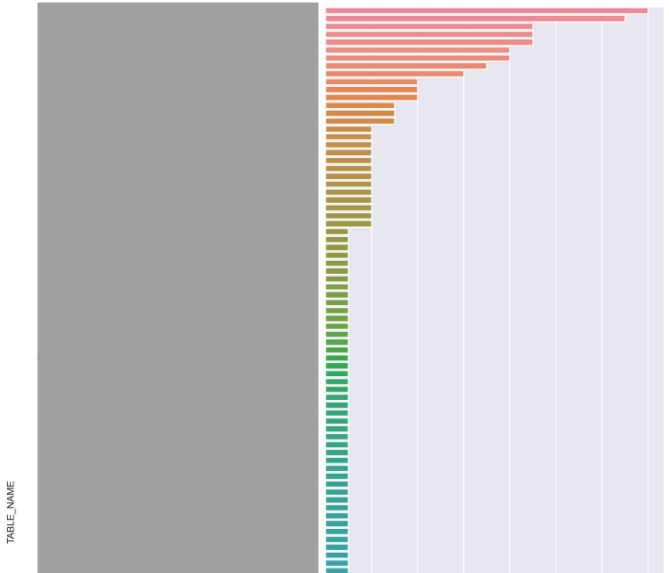
横軸は見切れていますが最大値14です。いくつかの部署の分析担当者に毎日活用されていそうなテーブルがある一方で、参照がまれなテーブルも複数見つかりました。
実はこの手法でカバーできない点について
筆者の知る限りにおいて、ACCESS_HISTORYをそのまま使うだけだといくらか不都合がある事がわかっています。
一つはタスクです。SnowflakeにはSQLを定期実行するスケジューラ的な機能(タスク)があるのですが、タスクの実行は特別なユーザであるSYSTEMによって実行されます。このときACCESS_HISTORYにもSYSTEMユーザが記録されます。この挙動はある意味もっともではあるものの、利用実態を把握したいという今回の目的には向きません。知りたいのはタスクを登録してそのテーブルを参照したいと考えたユーザ数であって、SYSTEMユーザが実行した事実ではないからです。
もう一つはSnowsightです。Snowsightの内部的な挙動として、WORKSHEETS_APP_USERというユーザを経由してクエリを発行することがあるようです。
ここの話によると、どうも内部的なキャッシュ等に使っているらしいですが、そうなると参照をどう数えればいいのか自明ではなくなってしまいます。
まとめ
- Streamlitで簡単なデモサイトを書きました
- おおまかにはACCESS_HISTORYビューは有用な情報が詰まっていて利用実態の把握に有益そうでした。
ただし、Snowflakeの使い方によっては素直な利用実態調査に難がある部分もありました。この辺りは手元で軽く実験する限りだと挙動がよくわからなかったので、ダッシュボードを整備するには要調査(あるいはSnowflake社への問い合わせが必要)なところかもしれません。